{kind=link}
{kind=link}
“人工嘴”在语音声学分析中的应用研究
[王莉 , 王晓笛
, 王晓笛* , 康锦涛, 盛卉, 李敬阳]
, 王晓笛, 康锦涛, 盛卉, 李敬阳]
|
|


第一作者简介:王莉(1969—),女,吉林舒兰人,学士,副研究员,研究方向为声纹鉴定。E-mail: wangli@cifs.gov.cn
“人工嘴”是一种可以模拟人嘴发声的放音装置。它在近场范围内能够精确模拟人嘴所产生的声场,专门用于电话、手机及电声元器件等传输和通信类产品中麦克风通路的声学特性的检测。本文主要介绍通过提取“人工嘴”播放的语音(测试语音)与源语音(音源)的语音质量感知评估(perceptual evaluation of speech quality, PESQ)得分、基频和能量、共振峰、感知线性预测系数和信道因子等五个声学参数,分析比较二者之间存在的差异,来评估“人工嘴”对语音声学特征的影响。通过实验可知,“人工嘴”作为一种新型的放音装置,在使用过程中对语音质量和语音声学参数的影响是客观存在的,但程度不同;差异最大值出现在PESQ的评测结果中。这为“人工嘴”在今后相关项目中的应用奠定了数据基础,具有一定的参考价值。
Mouth simulator, an audio device used to imitate human voice, can exactly mimic human mouth speaking to generate sound field in near range, having its special purpose for either sound transmission through telephone, mobile phone, acoustic components or detection of acoustic features about microphone channel in communication products. With the extracted voices of the sampling (broadcast by mouth simulator for test) and the source, the comparison was here made on five acoustic parameters of PESQ (perceptual evaluation of speech quality), fundamental frequency, formant, PLP (perceptual linear predictive) and i-vector so that the difference can be recognized between the sampling and source voice, making the impact assessed of mouth simulator on acoustic features. The experiment indicated that mouth simulator, as a new type of audio device, inevitably has its effect on speech quality and acoustic parameters in practical usage despite the different degree. PESQ evaluation showed the maximum difference.
在以往的研究中, 常考察同一说话人语音特征的稳定性、变异性以及不同说话人之间语音特征的差异性[1], 分析时大都提取说话人相同音节的基频、共振峰[2]、音强、过渡音征[3]等参数进行比较, 唯一难以控制的是音源的同一。随着科学技术的不断发展, 新型的仿生放音装置应运而生, 如何利用这些仪器设备为课题研究注入新的动力, 是现阶段值得思考的新问题。
“ 人工嘴” 是一种可以模拟人嘴发声的放音装置。它在近场范围内能够精确模拟人嘴所产生的声场, 专门用于电话、手机及电声元器件等传输和通信类产品中麦克风通路声学特性的检测。目前, 对它的研究主要围绕频率响应、最大输出声压级和谐波失真声学特性[4]等, 尚未发现与语音学分析相结合的实践研究。为了全面考察测试语音与源语音之间的特征差异, 本研究除采用基频、共振峰等常用参数外, 还引入2001年国际电信联盟(International Telecommunication Union, ITU)提出的语音质量感知评估方法评测语音质量和感知线性预测系数[5]、信道因子和动态时间规整(dynamic time warping, DTW)算法[6], 不断丰富和拓展实验设备和研究思路。“ 人工嘴” 能至少在200~8000 Hz频率范围内发出稳定的声信号, 一般在MRP处应大于100 dB。
笔记本电脑2台:ThinkPad X200(2.26GHz 2.27GHz CPU, 4GB RAM Windows 7 专业版); Adobe Audition 1.5专业音频编辑软件; 语音质量及声学参数相似度评价工具(PESQ算法、感知线性预测系数、信道因子和DTW算法); RS AM3000 型“ 人工嘴” :在距离“ 人工嘴” 嘴唇固定位置处提供一个持续稳定的, 低失真的宽频信号, 在输入电压为1 V(0.25 W)的驱动下, 25 mm MRP位置处最小持续声压级为106 dBSPL, 频带范围为100~10 000 Hz, 稳定工作的最大输入功率为10 W; 麦克风:AKG C-4000B, 电容式, 指向性:可在心型、超心型及全指向型之间进行切换, 灵敏度:-32 dBV, 频响范围:20~20 000 Hz。
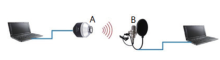
图1表示测试语音采集系统, 通过音频线将PC机与“ 人工嘴” 相连, 用PC机播放实验音源通过人工嘴放音, 比照使用者在使用麦克风录音时, 嘴与麦克风的距离(A-B)大约为13.5 cm, 固定人工嘴与麦克风的相对位置。并定义接收语音为测试语音。
 | 图1 测试语音采集系统Fig.1 Setup for acquisition of tested speech |
1.3.1 单频信号
选取初始值f0=100 Hz, △ t0=10 s, fk= kf0(k=1、2、3……34)的一组单频信号作为音源, 每5个音频信号为1组(t=60 s), 100~3400 Hz区间可分为7组, 如表1所示。
| 表1 单频信号频率与强度的取值范围 Table 1 Collected frequencies and intensities of single-frequency signal |
1.3.2 语音信号
1段时长为60 s的男性说话人读说语音。
通过视谱和定量测量发现, 测试语音在基频和能量帧参数(frame parameter, FP)变化不是十分明显, 为此我们引入了段参数(segment parameter, SP)和勒让德多项式参数(Legendre polynomial parameter, LP)进行分析评判, 通过对比经过“ 人工嘴” 传输后的语音与音源之间的基频包络变化来获取相关的目标情况。SP和LP描述的是基频和能量在某一个时间段的动态变化趋势, 相比FP而言, SP和LP反映的信息更加丰富和细致, 反映出的差异也会更加明显。
信道因子是基于感知线性预测系数(perceptual linear predictive, PLP)的提取结果而计算出的声学特征; Dehak等[7]提出了联合因子分析模型, 采用全空间建模, 对于一段语音而言, 可将其所有可变因素分为说话人空间和信道空间, 由于本实验中不涉及不同说话人, 因此得到的差异仅表示为信道差异, 即信道因子。
由于单频信号不符合PESQ、共振峰和信道因子的测试要求, 这里仅比较二者的基频和能量(FP、SP、LP及PLP), 如表2及图2所示。不同次测试语音与源语音之间存在时长不等, 同一音素无法自然对齐的现象, 因此在分析过程中引入DTW算法, 用于满足一定条件下测试语音和源语音之间的对应关系, 通过时间规整函数求取两段语音匹配时累计的最小距离。DTW表达式为:
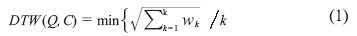
这里Q, C分别代表发送语音和源语音。
| 表2 单频信号各参数的数据 Table 2 Parameters of single-frequency signal |
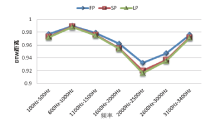
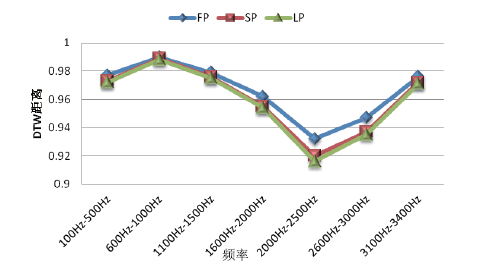 | 图2 单音频信号基频和能量参数Fig.2 Curves of single-frequency signal into its fundamental frequency and energy |
由图2知, “ 人工嘴” 对单频信号在FP、SP、LP三个特征参数上总体的变化趋势基本一致, 任意一条语音的得分结果均为FP> SP> LP。在100~3400 Hz频域范围内, 得分最大值出现在600~1000 Hz之间, 最小值均出现在2000~2500 Hz之间, 反映出单频信号在600~1000 Hz区间的基频和能量相对稳定, 与源信号最相近; 在2000~2500 Hz频域范围内基频和能量参数变化较明显, 与源信号差异相对较大。
表2最后一列为感知线性预测系数的分析结果, 在100~3400 Hz频域范围内, 该项分值不足0.32。分析原因主要是由于感知线性预测系数描述的是更深层的语音声学特征及语音对人耳听觉造成的影响等, 单频信号不能很好反映这些特性, 故得分结果明显低于其他参数。
为避免单次放音存在的不足, 将实验音源(一段时长为60 s的男性说话人读说语音)重复播放150遍, 各声学参数取均值和方差(表3), 来评估经过“ 人工嘴” 放音后的语音与源语音的异同。
| 表3 语音信号各参数的数据 Table 3 Data on parameters of speech signal |
由表3可知, 在基频和能量(FP、LP、SP)、共振峰、感知线性预测系数(PLP)、信道因子的分析中测试语音与源语音得分结果均较高, 说明“ 人工嘴” 这一放音装置对于语音在这几项参数中影响均较小。
值得注意的是, 由于测试语音所包含的信息量较单频信号更加丰富, 测试语音的感知线性预测系数分析结果较之前的结果要高, 基于感知线性预测系数提取的信道因子的得分也相对较高。感知线性预测系数作为一种深层的语音声学特征, 它每帧提取到的是一个39维的特征向量, 能够反映出比其他参数更加明显的特征差异, 因此它的得分结果相对其他参数要低。
PESQ的正常得分区间在1.0~4.5之间[8], 经过“ 人工嘴” 放音后的语音得分为3.404; PESQ是目前与平均意见值(mean opinion score, MOS)评分相关度最高的客观语音质量评价算法, 通常在数字语音通信中, MOS值在3.0分以上的语音可以被认为拥有比较好的语音质量[9, 10]; 因此, “ 人工嘴” 对测试语音在PESQ语音质量评测结果影响不大, 适用于相关领域的进一步研究。
方差反映出不同次测试语音得分与总分均值之间差异, 方差结果小, 说明各参数不同次测试语音之间的差异小、稳定性较高, 即“ 人工嘴” 的稳定性较高, 适用于重复性实验。
本研究结果表明, “ 人工嘴” 作为一种新型的仿生放音装置, 在使用过程中虽然对语音质量和语音声学参数有客观影响, 但并不显著。这一分析结果仅为后续实验提供数据参考, 是否适用还要依据具体情况分析判断。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|