

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
大数据环境下电子证据采集:一个二维采集框架
[张玉强1  , 顾辰
, 顾辰2 ]
, 顾辰|
|


第一作者简介:张玉强(1980—),男,江苏徐州人,硕士,工程师,研究方向为电子取证、智能信息处理。E-mail:yuq_zdf@126.com
电子证据采集是电子取证的关键步骤,关系到取证的效率和结果。传统的电子证据采集方法为电子取证的蓬勃发展奠定了基础,然而,大数据时代的到来给电子证据采集带来了新的问题和挑战。本文从大数据的内在特质出发,剖析电子证据采集当下面临的主要问题:证据数量庞大,证据来源多样,证据类型复杂,证据一致性难于保持,证据内在关联关系薄弱,采集无效数据过多等。鉴于此,本文提出了一个二维电子证据采集框架。该框架首先利用案例推理(Case-based Reasoning,CBR)对待采集的电子证据定位,以过往类似案例为经验,限定电子证据采集的位置;然后通过基于本体(Ontology)的专家知识库,借助本体描述,解决证据源多样问题,借助知识库推理机,挖掘出证据间关联关系,同时划定电子证据采集的内容。二者结合,从电子证据采集的位置和内容双重维度,最大程度地剔除了无关数据,提高了采集效率,减少了采集时间,避免了证据冲突,为电子取证后续工作的开展提供了高效、可靠的分析基础。
Digital evidence collection (DEC) is one of the most important steps for digital forensics, affecting the efficiency and final investigation results of the involved cases. Traditionally, DEC lays the foundation upon the emerging technologies of digital forensics. However, Big Data context brings new challenges to DEC because of the large quantity of evidence, diversity of evidence sources, complex evidence types, inconsistent evidence, poor internal relations among evidences and overmuch invalid data. Hence, this paper presents a two-dimensional framework for DEC. Firstly, the framework reuses the known experience from already-solved cases to orient the digital evidence with case-based reasoning approach. Secondly, with the assistance of the expertise knowledgebase built from ontology, the diverse evidence sources can be settled. Helped with the inference engine from the knowledgebase, the inner-relationship can be dug out among various evidence and delimit the evidence’ content for collection. By combination of the two dimensions - the orientation and the content for DEC, the invalid data can be eliminated, the efficiency improved and the conflict avoided among evidence, thus providing an efficiency-high and solid analytic basis for the follow-up task.
随着移动互联网、物联网和云计算技术的发展, 人类社会进入到大数据时代。大数据以其体量大、种类多、速度快、价值密度低等4大特质, 对社会发展的方方面面带来了深远的影响, 电子证据采集领域也概莫能外。传统电子证据采集更多考虑的是数据的完整性, 而忽视了取证后的数据分析, 因而无法适应大数据时代的新需求。为了应对大数据给电子证据采集带来的证据数量庞大、证据来源多样、证据类型复杂、证据一致性难于保持、证据内在关联关系薄弱、采集无效数据过多等问题, 国内外专家对此开展了相关研究。
Marziale等[1]认为大数据环境下的电子证据采集需要高效的计算系统运行取证工具, 并提出多线程的解决方案从证据中雕刻数据。Quick和Choo[2]通过总结前人研究提出使用数据挖掘、数据约简和子集、分流、智能分析等方法解决数据体量大问题。Kishore和Kapoor[3]认识到使用加密散列函数的电子证据采集工具在大数据环境下因花费漫长时间而变得不可行, 因此他们提出改进的并行加密散列函数加速镜像创建过程。Bashir和Khan[4]设计了一个分流框架, 提出将分流置于证据采集和分析之间。Turnbull和Randhawa[5]提出将专家知识封装到取证数据中, 使用多层本体抽取关键数据, 并从电子证据中抽取事件和社交网络。Quick和Choo[6]提出大数据取证缩减方法, 利用过滤技术, 选择关键数据成像和还原, 克服大数据带来的影响。
早期国内关于电子证据采集的研究主要集中于云计算对电子取证的影响[7, 8, 9], 有关大数据对电子证据采集影响的研究近年来才逐渐丰富。郭永健[10]通过解读大数据时代海量电子邮件分析的挑战和机遇, 提出通过邮件各元数据信息的分析与挖掘、邮件关系分析和邮件行为分析, 从而准确研判邮件联系人的关系、涉案人员生活规律的思路。高波[11]从制度到思维方面阐述了大数据对电子证据采集造成的影响, 指出大数据挖掘为电子证据收集提供了技术方案, 并进一步从制度和思维上给出了大数据下电子证据收集的应对策略。还有一些研究集中在大数据信息采集领域, 如罗恩韬等[12]结合传统BSP模型和前人研究成果, 提出了一种针对大数据时代的数据抽取模型。它利用拆分数据、分析数据、整合数据来提高数据的有效性。徐鸿志[13]指出借助大数据技术新的证据收集方法可以发挥更大的作用, 有效保证证据的真实性, 保障当事人的合法权益。另外, 国内取证龙头企业美亚公司[14]在其技术分享中提出数据预处理是应对大数据影响的关键。
综上所述, 当前国外对电子证据采集的研究, 都偏重于通过分布式、多线程软硬件技术、设计新型采集文件格式压缩数据或基于人工智能的分流方法来应对数据体量变大等问题。国内从制度思维或具体某项应用中提出了应对大数据影响的一些方法。但总的来说这些研究偏重部分方面或专用于处理某种设备, 不适应多样的数据源, 没有保证数据一致性, 难于挖掘出不同证据源之间的相关关系, 也没有从多个维度解决证据数据庞大问题, 因而不能有效过滤无关数据, 不能全面解决大数据给电子证据采集带来的挑战。
鉴于此, 本文提出一种新的二维电子证据采集框架, 该框架首先通过案例推理方法将证据采集位置限定于证据源指定位置范围内, 然后通过基于本体的专家知识库将采集内容限定在指定内容范围内。该框架利用过往经验最大程度提高了采集效率, 通过从本质上对证据源描述解决了证据源多样的问题, 利用知识库推理机解决证据间关联关系挖掘问题。同时, 通过指定位置范围、内容范围最大程度剔除无关数据, 减少了采集时间, 避免了证据冲突, 为后续证据分析提供了良好的分析基础。
大数据内在特质体现在其“ 4v” 特性上, 即大数据巨大的数据量与数据完整性(Volume), 在海量、种类繁多的数据间发现其内在关联(Variety), 更快地满足实时性需求(Velocity)以及相对于大数据海量数据信息的价值密度降低(Value)等。由此, 给电子证据采集带来的挑战主要有以下三点:
证据数量庞大的挑战。提到大数据, 首先被人们感知的就是海量的数据。随着社交网络的成熟、传统互联网到移动互联网的转变及移动带宽的提升, 除了个人电脑、智能手机、平板电脑等常见客户终端外, 更多更先进的传感设备、智能设备都将接入网络, 数据被大量生产。相关研究表明截至2013年底在取证焦点案件中, 有一半的案件取证涉及的数据超过“ 太字节” , 有五分之一的超过5 TB, 并且数据还在急剧增加。大量增加的数据造成传统的按位拷贝无法实现, 严重制约了电子取证工作的证据采集效率。
证据来源多样的挑战。在大数据背景下, 物联网技术、云技术、移动互联技术迅猛发展, 案件中涉及的证据源也日趋多样, 有计算机文件, 电话通讯录, 电话话单, 手机基站信号强度的跟踪信息, 音视频文件, 图像文件, 电子邮件, 社交媒体站点, 买卖交易记录, 电话GPS信息, 网络流量模式, 病毒入侵检测, 智能穿戴产品, 空气传感器文件等。多样证据之间没有统一的表示标准。
证据数据类型复杂、一致性难以保持以及关联性低的挑战。由于这些证据源所涉及的操作系统、文件格式、采集设备的多样性特征, 证据数据存在大量的专有数据格式, 数据之间难以合并。如NTFS格式的文件系统不能处理HFS文件。同时, 在大数据背景下, 证据数据类型复杂, 结构化、半结构化和非结构化数据大量涌现。证据类型及证据来源的双重差异, 导致证据间相关性难以发现, 证据一致性难以保持, 甚至证据之间互相冲突。
大量的犯罪案例证明相似的犯罪活动具有可比性的特征, 当人们在他们的系统中处理和存储文件时, 他们趋于持续使用特定的位置。为此, 可以从位置和内容两个维度限定证据采集。
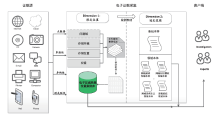
大数据环境下二维电子证据采集框架结构如图1所示。不同的证据源通过只读设备连接到电子证据采集设备中, 首先通过案例推理证据采集位置限定方法, 将采集位置限定在证据源的指定位置范围内, 然后通过基于本体的专家知识库采集内容限定方法, 将采集内容限定在指定内容范围内, 最后将采集结果呈现给相关人员。
 | 图1 电子证据采集二维框架Fig.1 The framework of two-dimensional digital evidence collection |
2.2.1 可行性分析
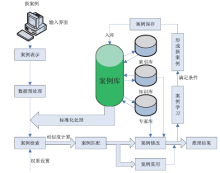
电子证据数量庞大, 来源多样, 类型复杂, 难以用规则或模型的方法表示, 而案例推理(Case-based reasoning, CBR)不需要严格的规则或模型, 通过借鉴过往经验对当前问题进行分析并给出解决方案。其工作原理如图2所示。
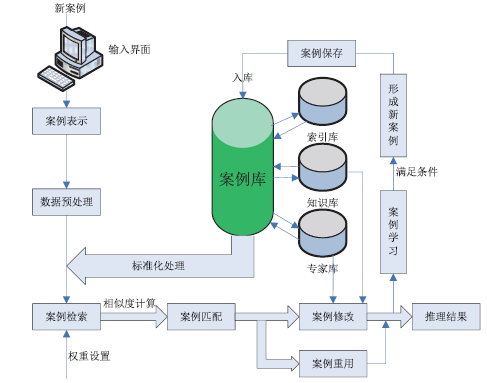 | 图2 案例推理的工作流程Fig.2 The operational process of case-based reasoning |
通常认为[15], 一个完整的CBR系统一般包括如下5个循环过程:案例表示, 案例检索, 案例重用, 案例修改, 案例保留。同时, CBR系统具有如下特征[16]:1)知识获取是获得过去发生过的案例的过程; 2)案例推理系统仅需从案例库中检索出相似案例, 容易实现; 3)由于案例库可以不断增长, 所以即使仅有少量案例, 案例推理系统也可以运行; 4)案例推理系统可以快速提供解决方案; 5)案例推理系统提供给用户的是具体的案例, 容易理解; 6)案例推理系统可以通过获得新案例来学习, 容易维护。所以通过设计基于案例推理的电子证据采集定位方法, 将采集范围限定在指定位置内, 实现从位置维度优化证据采集是可行性的。
2.2.2 开发方法
案例是案例推理的基础, 本文将过往电子取证中的证据采集经验描述成案例形式, 每一个案例是一个犯罪行为的概要信息, 用于识别罪行。电子证据采集案例使用三元组方法进行描述, 包括问题域、解决方案域和权重。问题域用来描述某种犯罪行为。如, 网络恐怖主义活动; 解决方案域表示该犯罪行为相关证据的系统环境及存放位置; 权重表示在该位置存放证据的可能性大小, 该值由领域专家设定。
文件路径的抽象描述是案例表示的基础。每个案例中电子证据存放的文件和文件夹名字或许不同, 但他们的在文件夹层级中的位置是相似的。因此需要在文件路径描述时去除所有个体信息, 最大化抽取共通信息。本文使用“ 卷” 表示盘符, 用“ 用户文件夹” 表示用户自定义的文件夹。如, 在网络恐怖主义犯罪中两个不同犯罪嫌疑人电脑中分别含有如下目录:“ D:\download\快牙” 和“ E:\快牙\下载” , 其中都存有宗教极端宣传音视频资料, 其文件路径可以抽象为“ 卷\用户文件夹” 。网络恐怖主义的部分案例表示如表1所示。案例按照领域分类, 存储在案例库中。
| 表1 网络恐怖主义案例结构描述(部分) Table 1 The frameworks of cyberterrorist case (partial) |
案例检索是通过访问案例库中过去同类问题的解决方案从而获得当前问题解决方案的一种推理方法。案例检索的结果可以是一个最佳案例, 也可以是一组相似案例, 然后综合各相似案例的解决方案, 形成最佳解决方案。案例检索的效率和检索方法密切相关, 目前常用的检索有K近邻法, 归纳推理和知识引导等方法。案例推理的电子证据采集定位方法采用K近邻法, 通过计算各个属性的相似度加权值找出最相近的案例。
2.2.3 工作流程
案例推理电子证据采集定位方法工作流程如下:
Step1:首先将待采集案件描述成新案例, 问题域就是犯罪行为, 然后根据该问题域, 在案例库搜索同类问题优先级最高的文件位置, 即权重最大的位置, 从中发现相关证据, 并根据结果计算出当前采集结果和已知案例的相似度, 从中选取最接近的Top 5案例。
Step2:以Top 5案例为基础, 按照相似度从高到低的顺序, 搜索每一个过往案例中其他证据位置, 扩大搜索范围, 采集相关证据。
Step3:根据采集结果使用案例、修改案例和保存案例。
该方法首先将采集活动限定于最可能区域, 然后扩展到最相似案例组中其他区域, 既提高了搜索效率, 又不会无限扩大搜索范围, 具有良好的收敛性。
案例推理的采集定位方法通过重用过去的采集经验, 将采集缩小到特定的范围, 限定了电子证据采集的位置, 提高了采集效率。为了进一步明确电子证据采集的内容, 克服证据源多样问题, 挖掘出电子证据间的相关关系, 保持数据一致性, 下文将利用基于本体专家知识库的方法, 进一步从内容维度限定电子证据采集范围。
2.3.1 可行性分析
大数据背景下, 证据源日趋多样, 证据链错综复杂, 所有这些都限制了电子证据采集工作的进一步推进。考虑到本体具有能够对层次结构、图表、实体及其相关关系进行自然编码和可靠描述, 且本体的数据描述与人们的直观认识十分接近, 易于用图表示(其中对象是节点, 属性是链接)等优点, 将本体引入电子取证领域是确实可行的[17]。相关研究业已展开[18, 19, 20]。
上述研究在一定程度推动了本体在电子证据采集领域的发展, 给电子证据采集的未来研究方向提供了有价值的参考。但已有的电子证据采集本体在实施过程中仍存在如下缺陷:首先, 建立本体的语言, 如XML, RDF等, 不利于本体推理; 其次, 多使用分层的思想, 但没有将案件领域专家知识用于本体, 没有考虑多领域本体构建。为此, 本文在吸收前人研究的基础上, 重新设计电子证据采集的本体专家知识库, 将其分为两层:基础层本体和领域知识层本体, 利用W3C推荐语言OWL2开发本体, 使之更利于共享和推理。
2.3.2 开发方法
本文构造的专家知识库由二层本体构成, 基础层本体和领域知识层本体。开发按照4步法[21]实施, 即识别开发目的— 建立本体— 评估— 文档。其中, 基础层本体开发的目的是:理解设备本质、文件系统、操作系统、映像格式和数字签名等取证通用基础概念, 解决证据源多样问题和证据类型复杂问题。因此, 基础层本体包括:存储媒介类, 主要是描述存储证据的媒体本质, 包括硬盘、USB sticks、sd、tf、cf、mmc、xD、SDHC、记忆棒、sim和云等。其中云可以是任何虚拟空间, 如互联网、内联网和外联网等, 具体存储设备有磁性设备、闪存设备和光学设备; 文件系统类, 主是描述用于组织和管理证据的文件系统格式, 如Windows的NTFS、FAT32、FAT、Ubuntu/Linux的Root Director和EXT3等; 操作系统类, 主要提供现存的操作系统描述, 包括Windows、ios、Android等; 映像格式类, 主要描述取证映像, 包括DD、EWF、AFF、DEG和SDEB等。数字签名类, 是关于证据完整性的描述, 包括CRC和时间戳等。基础层本体类的关键属性有:isA、isType、isLocatedAt等。图3是基础层本体部分示意图。
 | 图3 基础层本体(部分)Fig.3 Ontological base layer (partial) |
领域知识层本体的开发目的是:理解各个犯罪相关领域的重要概念和属性, 刻画领域特征。包括:黑客类领域本体, 侵权知识产权领域本体, 网络恐怖主义领域本体等。每个领域本体由于特性不同, 其证据采集的数据也不尽相同。下面以网络恐怖主义领域知识本体为例介绍其开发方法。根据美国联邦调查局的定义, 网络恐怖主义就是任何组织或个人发动的有预谋的, 带有个人的或政治的动机, 利用网络并以信息系统、计算机系统、计算机程序、数据以及其他电子交流、转运和存储方式为目标, 以破坏目标所有者的政治稳定、经济安全或社会秩序, 制造轰动效应为目的的恐怖活动。因此, 其相关概念可以抽象为动机、实践、行为人、目的、袭击目标和袭击效果等6个子类。其中, 动机是行为的动力, 主要有政治、民族、宗教、经济等; 实践是恐怖主义活动的具体实施方法, 如拒绝服务攻击、网站污损、破坏数据、筹款招募等; 行为人是发起网络恐怖主义活动的组织或个人, 包括疆独组织、藏独组织、宗教极端势力、境外反华黑客组织等; 目的是攻击活动要达到的目的, 主要包括直接目的和间接目的, 可分为摧毁、干扰、威胁、强制要求、抗议、盗取、恐吓、宣传、渗透等; 袭击目标是攻击作用的对象, 主要有政府部门、重要组织、关键人物等; 袭击效果是攻击产生的实际作用, 包括无效、一般效果、大效果和灾难性效果等。领域知识层本体类的属性有:isType、hasActor、hasKey、sameAs和similarAs等。图4是领域知识本体的部分示意图。
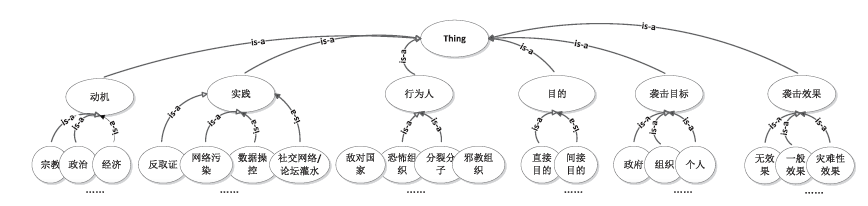 | 图4 领域知识层本体(以网络恐怖主义为例)Fig.4 Specific ontological domains (sectional) |
2.3.3 工作流程
基于本体的专家知识库划定电子证据采集内容的工作流程如下:
Step1:设定搜索领域范围(或不设定, 如果不设定, 则搜索范围为所有领域本体)。
Step2:当前证据源中的证据数据按照领域本体生成类的实例。
Step3:实例通过专家知识库推理机合并或给出相关信息。
Step4:输出最终采集结果。
专家知识库将采集内容限定于特定领域内, 从而进一步解决证据数量庞大的问题。如对于网络恐怖主义的采集, 其内容限定在效果、动机、实践、目标中, 满足的条件是:效果> 小(恐怖袭击不可能为了无效或小效果); 动机=政治或宗教或社会动机(恐怖分子的恐怖活动具有明显的政治、宗教或社会动机); 实践=数据操作(网络恐怖主义攻击通常由恶意行为构成, 如使用病毒、木马和蠕虫干扰操纵数据的网站); 目标=组织或机构(网络恐怖行动通常以组织或政府机构作为攻击目标)。
专家知识库通过内含的知识库推理机将多个电子证据数据合并或建立关联, 从而解决证据相关性和一致性问题。部分合并过程如图5所示。对于电子证据源多样问题, 专家知识库基础层本体描述了证据源的本元信息, 以及其内含的文件系统、操作系统等的本质信息, 因此他们含有的相关证据可以被作为本体子类的实例, 而不用考虑其所属的特定的设备。
 | 图5 本体推理过程(部分)Fig.5 Ontological SPARQL reasoning (partial) |
二维电子证据采集框架通过位置、内容二重维度限定采集范围。其中, 案例推理限定电子证据采集位置方法根据过往采集经验, 搜集最可能的证据位置, 通过计算相似度, 选取最相似数个案例, 按照选取的案例扩大搜索范围, 并将搜索范围限定在这些案例定义的范围中, 既最大可能保证了案例数据完整性, 又具有良好的收敛性。同时, 该方法灵活, 不局限于文件类型, 仅关注已知位置, 降低搜索范围, 提高采集效率。基于本体的专家知识库在位置维度限定的基础上, 通过本质描述, 搜索指定领域内容, 剔除了复杂的数据源处理过程, 解决了数据源多样问题, 通过专家知识库推理机将采集的证据合并或挖掘出关联关系, 使得采集结果更精准、精简。
除了数据量大、证据源多样, 证据相关性不强等上述问题外, 电子证据采集还存在如下问题:
1)时间线不统一问题。由于采集证据中常存在时钟漂移、时钟偏移甚至是时区差别, 以及对证据时间戳解释不同等问题导致证据时间线不统一。为此, 下一步考虑在专家知识库中加入统一的时钟校准和时间戳表示, 按照时间线重构证据序列。
2)采集结果显示直观友好问题。当前以二维表的形式将采集结果呈现给取证人员, 在很大程度上制约了取证人员对案件的分析研判和深度挖掘的想象空间, 无法完整理顺数据中所存在的“ 案” 、“ 人” 、“ 物” 的关联关系。下一步拟将大数据可视化技术用于采集结果表示, 使结果更直观, 更利于分析。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|